Innovations for Community Services pdf pdf
Teks penuh
Gambar
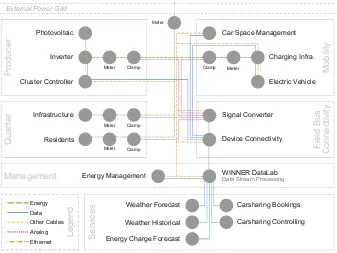

![Fig. 3. Structural dynamic of agent’s network over three periods: dashed red line withsymbol ‘[]’ reveal forlabel in symbol ‘[]’ illustrate RMT P with major topic; solid blue line with label without RDI with the number of interactions (Color figure online)](https://thumb-ap.123doks.com/thumbv2/123dok/3934641.1878061/61.439.57.397.54.348/structural-dynamic-network-periods-withsymbol-forlabel-illustrate-interactions.webp)
Garis besar
Dokumen terkait
Tujuan pengendalian dalam percobaan adalah mengatur situasi di mana pengaruh variabel yang dimanipulasi pada variabel dependen dapat diselidiki.
yang mempengaruhi perilaku konsumen dalam pengambilan keputusan.. pembelian,
pH adalah besaran yang digunakan untuk mengukur kadar keasamaan suatu larutan.. 3) Tuliskan setiap pasang titik (x,y) yang diperoleh. 4) Gambarkan setiap pasang titik
Keunggulan jagung QPM adalah kandungan asam amino esensial lisin dan triptofan yang lebih tinggi, dua kali dari jagung biasa yang akan berperan meningkatkan kesehatan anak
Tujuan Penelitian ini adalah : (1)Untuk Mengetahui Kategori Tingkat Transparansi Pelayanan Santunan di Kantor Jasa Raharja Sidoarjo.(2)Untuk Menguji Perbedaan Antara
• Setelah bahan pustaka diterima dan bahan pustaka tersebut diterbitkan oleh UK/UPT sendiri dan bukan dalam bentuk publikasi berkala ilmiah maka pengelola informasi/pustakawan
Sehingga dapat disimpulkan bahwa dari hasil penelitian menunjukkan kinerja mengajar guru bahasa Inggris pascasertifikasi di SMA Negeri sekecamatan Demak adalah baik..
(7) Ada interaksi antara metode pembelajaran dengan kemampuan menggunakan alat ukur dan sikap ilmiah terhadap prestasi kognitif (p-value = 0,029). Hal ini berarti bahwa
