Programmin Lerl Free ebook download
Teks penuh
Gambar
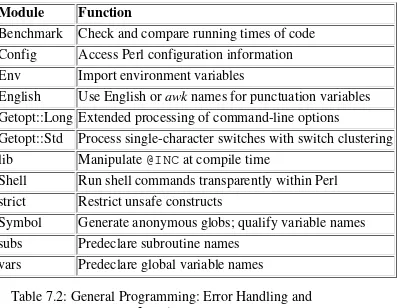
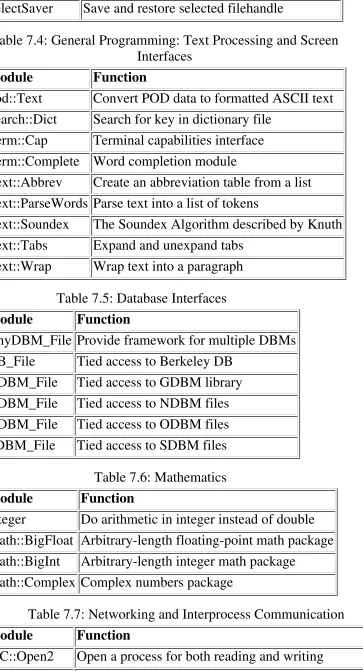
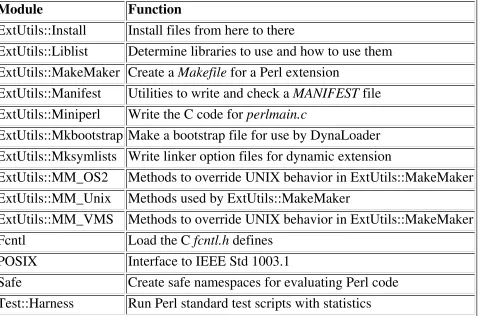

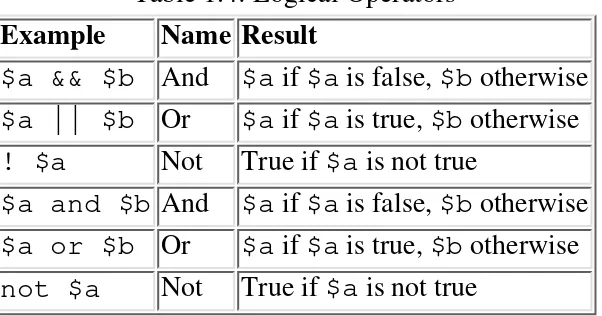
Garis besar
Dokumen terkait
Pernyataan tersebut sesuai dengan pendapat Nurwidodo (2012, hlm. 151), Gurulhanyalmengajarkanpmusiklsebataslhanyapbernyanyilataulmenggambarpsajaptanpa adanyalpemanfaatanpalat
Setelah mendapatkan pemahaman, mampu mengenal masalah, dan dapat mengambil keputusan, keluarga dapat memulai untuk merawat anak retardasi mental dengan membantu dalam
I think we’re going to see that emerging as there’s more access and more tools for people to do stuff with their data once they get it through things like the health data
Threat aktif merupakan pengguna gelap suatu peralatan terhubung fasilitas komunikasi untuk mengubah transmisi data atau mengubah isyarat kendali atau memunculkandata atau.
Efisiensi total yakni efisiensi antara instalasi produksi hidrogen dengan reaktor nuklir (sistem kopel) menunjukan tendensi yang sama dengan efisiensi pada transfer
Data penelitian ini adalah tuturan yang terdapat pada wacana “Pojok Mang Usil” edisi Agustus 2014 yang mengandung implikatur konvensional dan implikatur
To maintain the heritage language, mixed marriage families especially the children. also need to use the heritage language to their siblings
Diberitahukan dengan hormat kepada para Direktur perusahaan yang telah memasukkan dokumen penawaran untuk pekerjaan Penambahan Lajur Gedung Balai PKB Amplas
