HYPERGRAPH-PARTITIONING PADA CO-AUTHORSHIP GRAPH UNTUK PENGELOMPOKAN PENULIS BERDASARKAN TOPIK PENELITIAN
Teks penuh
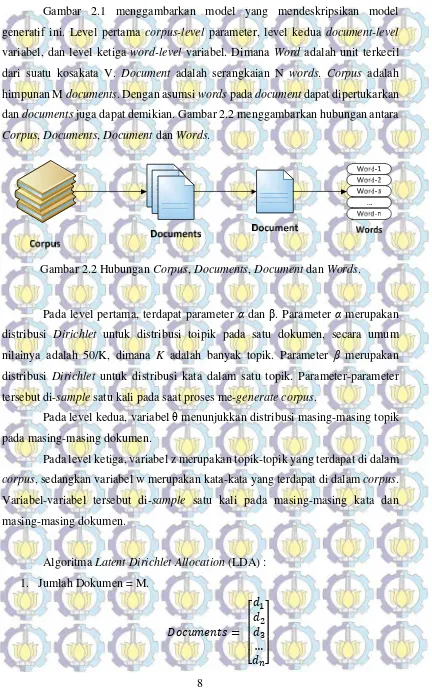
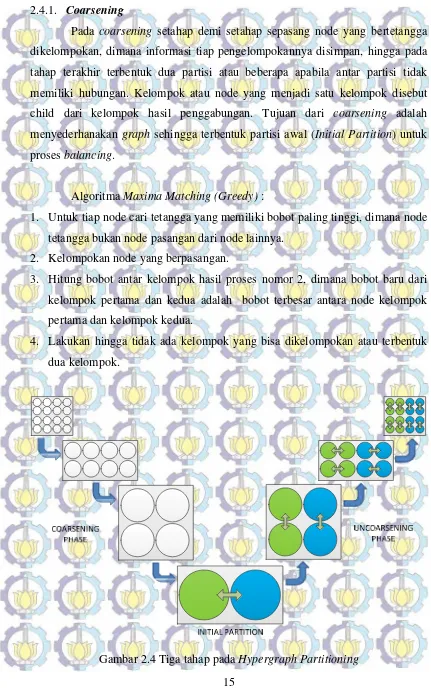
Gambar








Dokumen terkait
Garis penghubung pusat massa dan pusat geometri adalah sebuah sumbu pada simetri inersial, dan garis ini berada pada bidang tegak lurus terhadap sumbu tensor
Jika suatu baja didinginkan dari suhu yang lebih tinggi dan kemudian ditahan pada suhu yang lebih rendah selama waktu tertentu, maka akan menghasilkan struktur mikro
Telah dirancang sebuah prototype ruang penyimpanan benih padi berdasarkan pengontrolan temperatur dan kelembaban. Berdasarkan data referensi yang dikumpulkan, diperoleh
Analisis Tingkat Kepuasan Pasien Intern dan Ekstern Terhadap Mutu Pelayanan Dalam Rangka Meningkatkan Admisi Rawat Inap PT Rumah Sakit Pelabuhan Surabaya,
Kajian ini telah berjaya menghasilkan satu set IPPI yang boleh digunakan sebagai alat pengukuran personaliti Muslim dalam aspek yang berkaitan dengan gelagat
Setelah data terkumpul, teori resepsi pembaca dan aliran structuralism dalam teori resepsi pembaca akan digunakan sebagai pisau analisa untuk mengkategorisasikan pendapat para
Tetapi kepastian disetujuinya baru akhir Mei 2009, tepatnya 29 Mei 2009, sehingga kegiatan baru bisa dilaksanakan bulan Juni 2009, di mana pada bulan itu hujan sudah tidak
This survey project covered the following people groups in the districts of Tawang, West Kameng and East Kameng: Tawang Monpa, Dirang Monpa, Kalaktang Monpa, Sartang, Lish,
