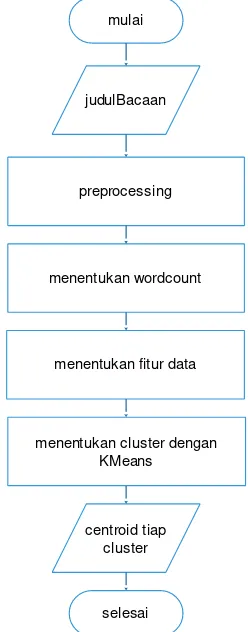
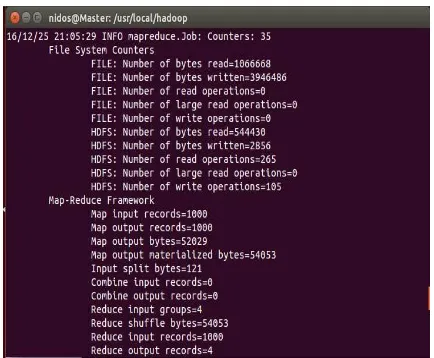
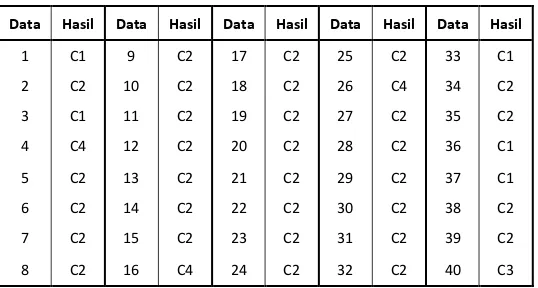
ANALISIS JUDUL MAJALAH KAWANKU MENGGUNAKAN CLUSTERING K-MEANS DENGAN KONSEP SIMULASI BIG DATA PADA HADOOP MULTI NODE CLUSTER
Teks penuh
Gambar
Dokumen terkait
Sistem pengurusan yang akan dil e ngkapi dengan enjin pencari yang akan memudahkan pencarian maklumat.. Pengguna hanya perlu m e naip kat a
cenderung mudah dialihkan dari tugas yang sedang dikerjakan yaitu mengatasi tingkah laku peserta didik yang senang ribut ketika mengerjakan tugas. Sikap seorang guru
Variabel yang dominan pengaruhnya terhadap minat beli helm INK pada mahasis- wa Fakultas Ekonomi Universitas Slamet Riyadi Surakarta adalah keunggulan citra merek,
Berdasakan data diatas, KSP Giri Muria Group dalam menetapkan nisbah menggunakan persentase yang telah ditentukan besarnya diawal seperti pada lembaga konvensional
Pemetaan batimetri di perairan dangkal tidak menggunakan kapal dengan ukuran yang besar seperti yang digunakan di laut, hal ini dikarenakan pada perairan dangkal
Identifikasi adalah apabila manjemen perusahaan mengetahui dan menyadari bahwa telah atau akan terjadi situasi yang tidak diinginkan dalam perusahaan. Identifikasi
Terdapat 3 responden yang mengalami penurunan nilai kenyamanan pada kelompok rendam kaki dengan selisih 5,17 dan 21 responden mengalami peningkatan kenyamanan dengan
Kulit pohon ek putih biasanya direbus atau dikukus untuk menghasilkan cairan yang dapat dioleskan pada daerah anus yang terdapat ambeien atau dijadikan teh
