getting data right Tacking the challenges of Big Data volume and Variety pdf pdf
Teks penuh
Gambar

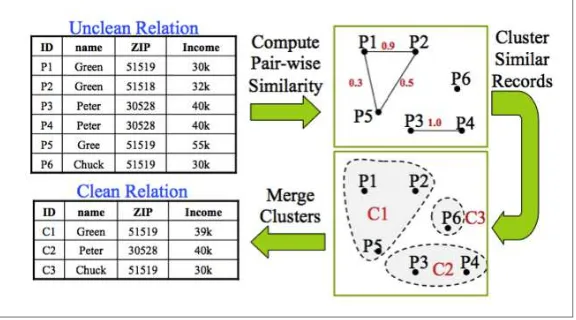

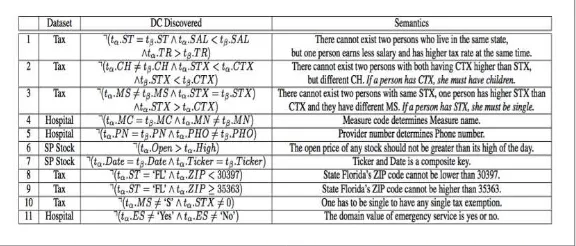
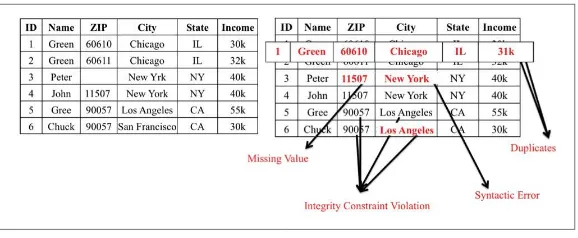
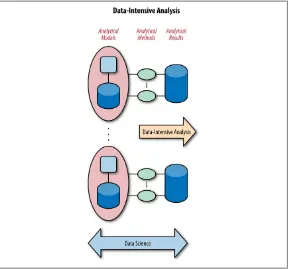
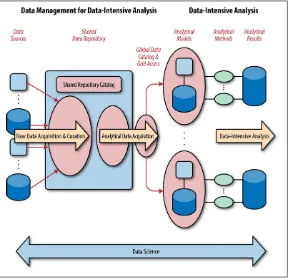
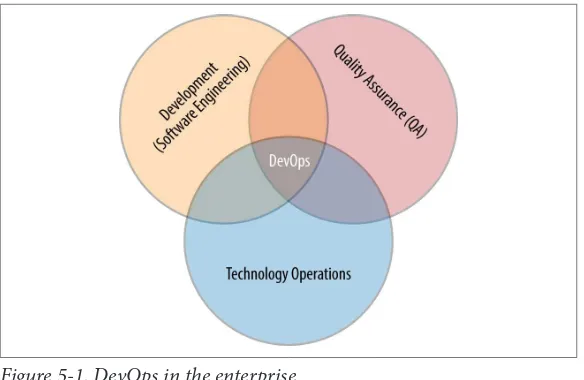

Dokumen terkait
Tujuan Penelitian ini adalah : (1)Untuk Mengetahui Kategori Tingkat Transparansi Pelayanan Santunan di Kantor Jasa Raharja Sidoarjo.(2)Untuk Menguji Perbedaan Antara
Analilisis koefisien determinasi menunjukkan hasil bahwa nilai R square (R 2 ) sebesar 0,630; hal tersebut dapat disimpulkan bahwa sumbangan pengaruh yang
• Setelah bahan pustaka diterima dan bahan pustaka tersebut diterbitkan oleh UK/UPT sendiri dan bukan dalam bentuk publikasi berkala ilmiah maka pengelola informasi/pustakawan
Angka ini menunjuk- kan bahwa respon petani terhadap teknologi oleh petani kedelai lahan sawah di Kabupaten Bojonegoro, lebih tinggi dibandingkan dengan respon petani
Sehingga dapat disimpulkan bahwa dari hasil penelitian menunjukkan kinerja mengajar guru bahasa Inggris pascasertifikasi di SMA Negeri sekecamatan Demak adalah baik..
Salah satu alternatif solusinya adalah dengan membuat suatu sistem keamanan sistem jaringan komputer, yaitu proxy anti virus dan di kombinasikan dengan mikrotik
Sistem Informasi Eksekutif adalah sistem yang dibuat hanya untuk digunakan oleh kepala perpustakaan. Permasalahan yang dihadapi adalah banyaknya data yang terdapat didalam
Tujuan penelitian ini adalah untuk membuktikan hipotesis bahwa pembelajaran dengan menggunakan model inside-outside circle akan meningkatkan minat belajar pada mata
