stream processing Ebook free download pdf pdf
Teks penuh
Gambar
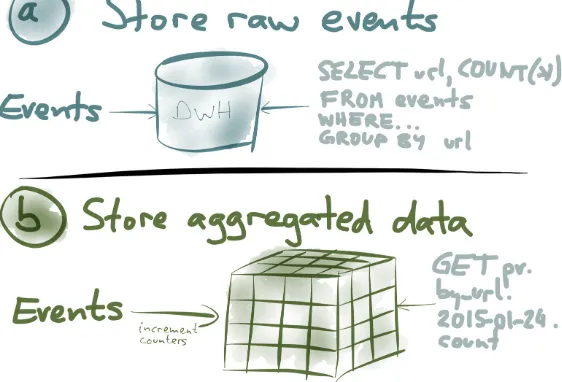

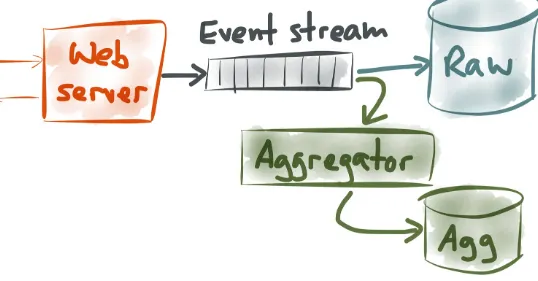

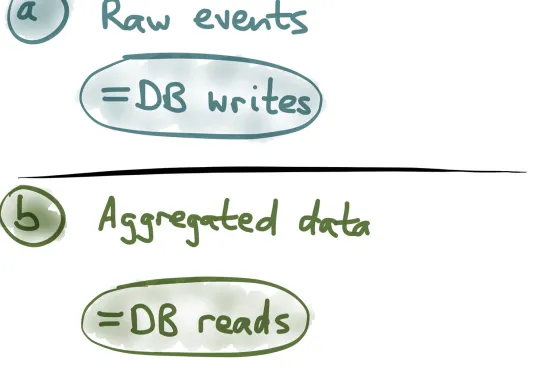
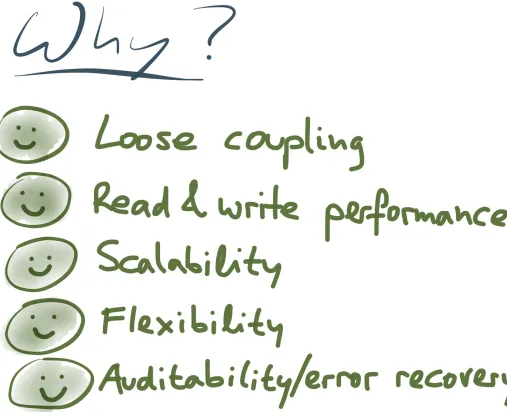




Garis besar
Dokumen terkait
Studi Penelusuran Terhadap Kemandirian Lulusan SMALB X Di Kabupaten Banjar.. Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu
Konfirmasi: Guru mengkonfirmasi bila terjadi perbedaan pendapat tentang Annelida, Mollusca, Arthropoda, Echinodermata.Secara klasikal siswa menyepakati hasil pengembangan
1. Dekan Fakultas Keguruan dan Ilmu Pendidikan Universitas Muria Kudus, Sekaligus sebagai Dosen Pembimbing 1 yang telah memberikan bimbingan mulai awal sampai
Capaian pembelajaran yang sudah dirancang dalam silabus Geografi Regional bertujuan untuk: (1) Mempelajari interaksi, interelasi, dan interdependensi serta
Puji syukur kehadiran Allah SWT atasa segala rahmat,hidayah serta pertolonganya sehingga skripsi dengan judul ”Pengaruh Share Growth, Ukuran KAP, Pergantian
support better decision making by contributing a greater insight into risks and their impacts .” Manajemen resiko adalah suatu proses yang terdiri dari
Untuk dapat hadir dalam acara pembuktian dokumen isian kualifikasi yang telah disampaikan kepada kami, pada :.. Hari/ Tanggal : Rabu, 11 November
If the casinos all offered 24 hour free daycare for all casino players those parents who are so far gone in their addiction will not have to make the decision of what to do with
