Perbandingan PNN dan LVQ dalam Identifikasi Jenis Bercak pada Daun Cabai
Teks penuh
Gambar
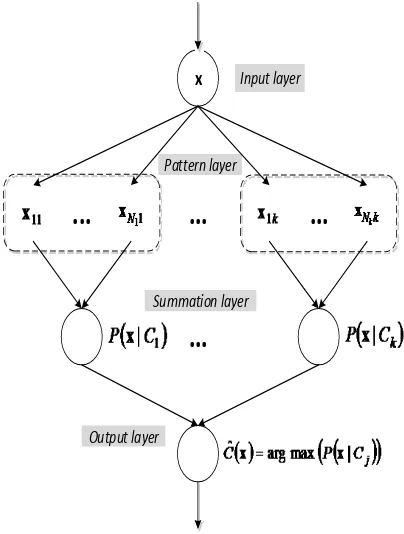


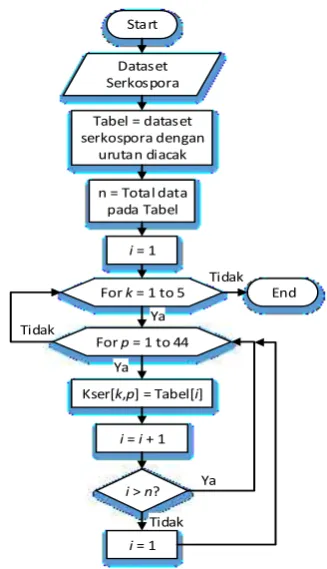
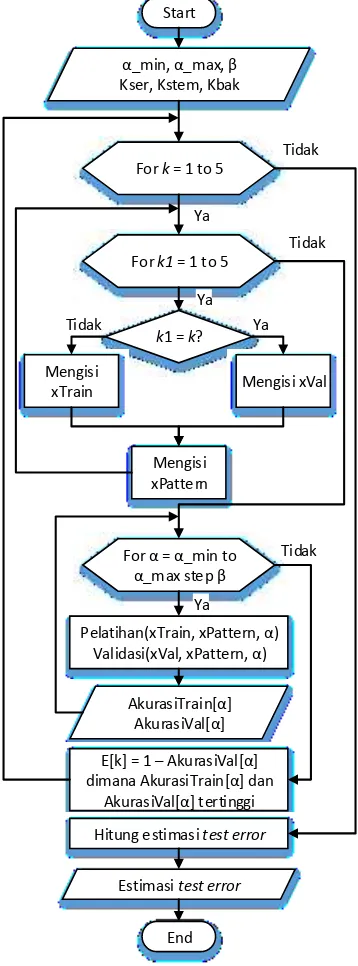

Dokumen terkait
ED PPSAK 7 tentang Pencabutan PSAK 44: Akuntansi Aktivitas Pengembangan Real Estat telah disahkan Dewan Standar Akuntansi Keuangan pada 12 Oktober 2010.. Oleh karena itu,
Untuk mengetahui terdapat perbedaan pengaruh mengenai kemampuan koneksi matematis siswa dalam pembelajaran yang menggunakan pendekatan kontekstual berbasis
Aset dan liabilitas pajak tangguhan diakui untuk semua perbedaan temporer yang dapat dikurangkan dan akumulasi rugi fiskal yang belum digunakan, sepanjang besar
bahwa untuk menjamin kelancaran pelaksanaan pengadaan barang / jasa ( pelelangan ) secara elektronik dan menjaga kelangsungan sistem pengadaan secara elektronik di
Hasil penelitian memberikan kesimpulan bahwa Baitul Maal Wattamwil Usaha Gabungan Terpadu Sidogiri dalam praktik Akuntansi ijarah lembaga keuangan syariah menerapkan akad
Penelitian ini bertujuan merancang dan membuat sistem kontrol mesin sortasi untuk buah manggis yang meliputi perputaran konveyor rantai, merancang dan membuat sistem
Cermatilah setiap hal yang ditawarkan, mulai dari jenis profil, connector, pengaku atau bracing, tumpuan khusus kuda-kuda, sertifikat kadar lapisan anti karat atau
Dengan metode deskriptif ini, penulis mendeskripsikan tingkat pencemaran tanah di Kecamatan Rancaekek Kabupaten Bandung, sumber pencemaran tanah dan selanjutnya
