mapping big data A data Driven Market Report
Teks penuh
Gambar
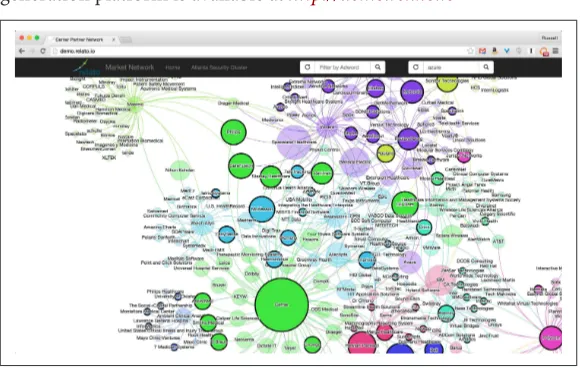
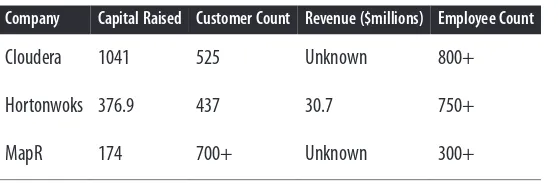
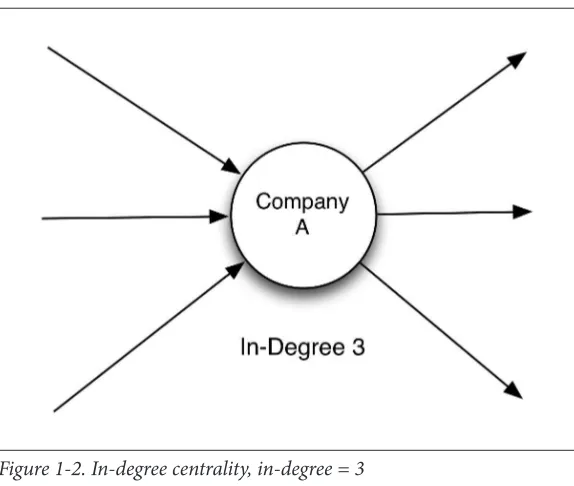

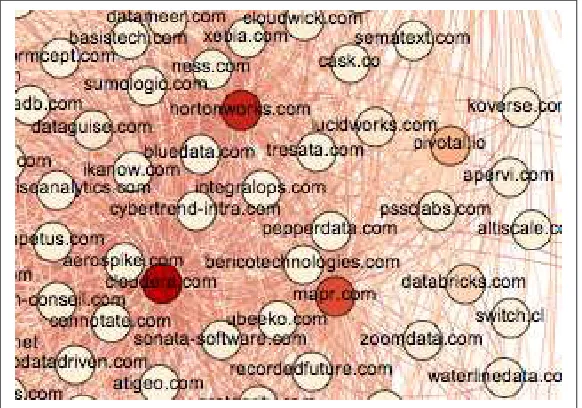

Dokumen terkait
Analisis Struktur Pasar dan Penetapan Harga pada Industri Telekomunikasi Telepon Seluler di Indonesia.. Universitas Pendidikan Indonesia | repository.upi.edu
membuat produk dari daur ulang limbah melalui model
Konformitas teman sebaya yang berada pada tataran remaja karang taruna di Dusun Gamping Desa Jambean, Sragen Jawa Tengah memiliki hubungan yang sigknifikan dengan perilaku
Beberapa hasil penelitian di Lahan kering Alfisol di Jawa menunjukkan bahwa pemberian pupuk 25 kg Urea/ha pada tanah dengan kandungan bahan organik rendah dinilai cukup untuk
Hipotesis yang diajukan dalam penelitian ini ialah: (1) eksplan nenas yang terenkapsulasi akan mengalami morfogenesis pada media yang mengadung auksin dan sitokinin, (2)
Tujuan pada penelitian ini adalah 1) untuk mengetahui perkembangan harga kedelai di tingkat KOPTI tahun 2010–2012. 3) Untuk mengetahui pengaruh perubahan harga kedelai
Substitusikan ini ke dalam fungsi (9), maka elastisitas perrnintaan input terhadap perubahan harga output dapat diperoleh sebagai berikut:. Lima butir tersebut di atas
Perusahaan tidak tahu seberapa besar kekuatan dan kelemahan-kelemahan apa saja yang ada pada perusahaan, manakala perusahaan telah semakin berkembang maka laporan keuangan
