Big Data Analytics Methods and Applications pdf pdf
Teks penuh
Gambar

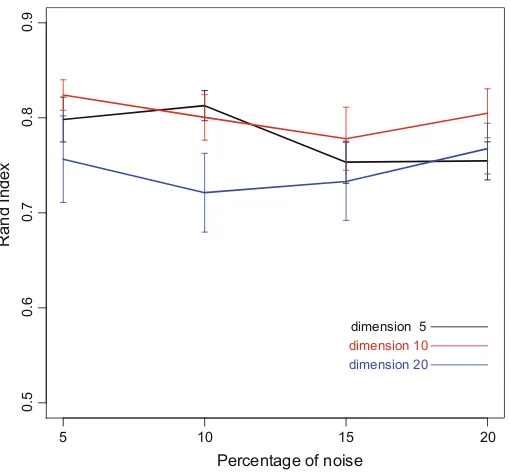
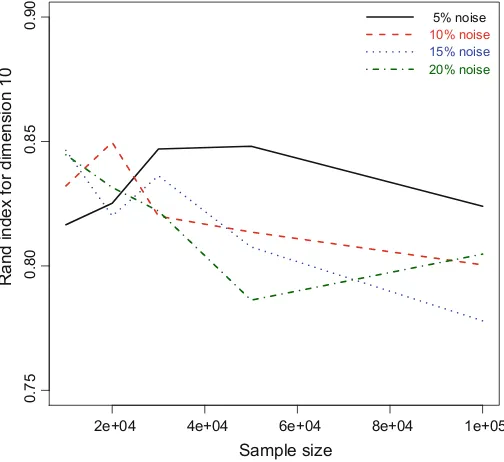
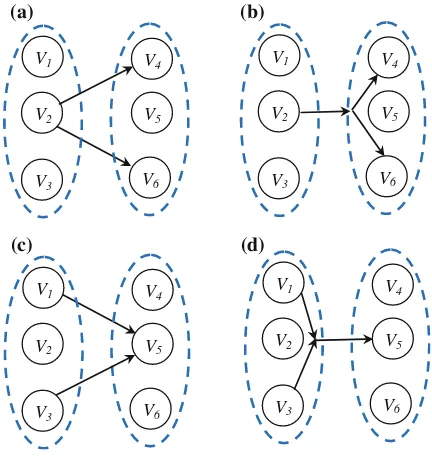
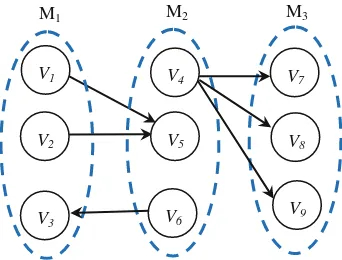

Dokumen terkait
Tujuan yang akan dicapai dari Tugas Akhir pembuatan Sistem Informasi Perpustakaan Booking Online ini adalah:. “Membuat sistem informasi perpustakaan booking online melalui web dan
Penelitian ini dilakukan dengan tujuan untuk mengetahui Sikap Masyarakat di Surabaya dalam menonton tayangan acara Reality Show Uya Emang Kuya di SCTV.. Dengan menggunakan
Lirik lagu “Bibir” yang dipopulerkan oleh penyanyi Samantha Band adalah sebuah proses komunikasi yang mewakili seni karena terdapat informasi atau pesan yang
Selama kegiatan diskusi kelompok berlangsung, tiap siswa diharapkan aktif untuk saling berbagi ide dalam menganalisis dan membuat katagori dari unsur- unsur
Tujuan dari penelitian ini adalah menganalisis faktor-faktor yang memotivasi manajemen perusahaan melakukan Tax Planning dalam beberapa perusahaan Industri Kimia di
Kemudian program kompensasi juga penting bagi perusahaan, karena hal itu mencerminkan upaya organisasi untuk mempertahankan sumberdaya manusia atau dengan kata lain agar
CHAPTER IV FINDING OF THE RESEARCH 4.1 The Reading Comprehension of Recount Text of the Eighth Grade Students of SMP NU Al Ma’ruf Kudus in Academic Year 2012/2013
Both of subcutaneous and intraperitoneal ways will interact systematically in the body, so that increasing width of lung connective tissue due to Bleomycin application
