View of PENDETEKSI KESAMAAN KATA UNTUK JUDUL PENULISAN BERBAHASA INDONESIA MENGGUNAKAN ALGORITMA STEMMING NAZIEF-ADRIANI
Teks penuh
Gambar
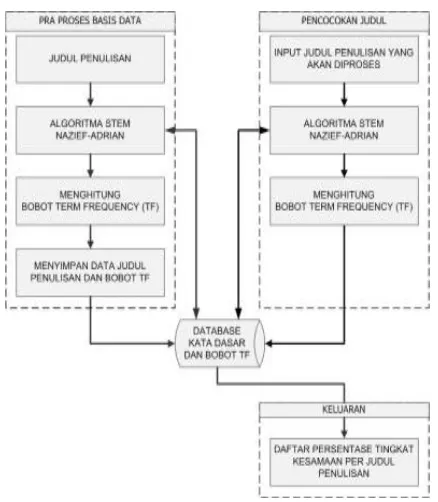
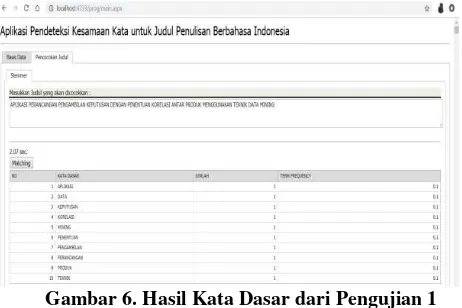
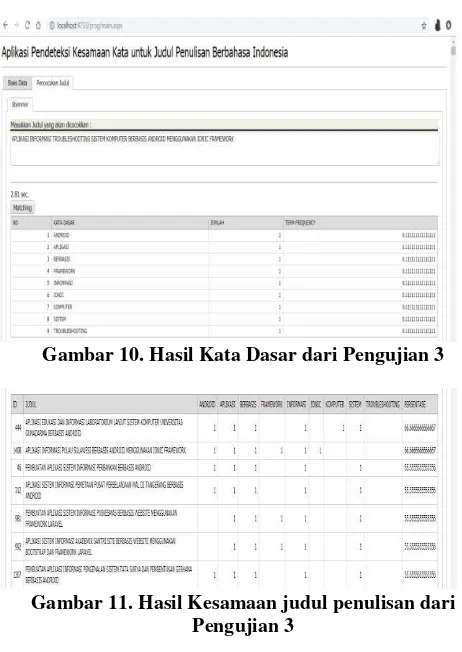

Dokumen terkait
Diindikasikan pada pasien dengan iskemia yang diketahui angina atau nyeri dada tanpa aktivitas, pada pasien kolesterol dan penyakit jantung keluarga yang mengalami nyeri
Dari latar belakang yang telah dijabarkan di atas, maka yang menjadi rumusan masalah dalam penelitian adalah: adakah hubungan antara citra diri dengan self-esteem
Berdasarkan tabel hasil analisis jalur di atas, dapat diuraikan sebagai berikut, yaitu Variabel remunerasi mempunyai pengaruh searah terhadap efektivitas kerja di Kantor
personality disorder) memiliki rasa bangga atau keyakinan yang berlebihan terhadap diri mereka sendiri dan kebutuhan yang ekstrem akan pemujaan.. berharap orang lain melihat
paper ini meneliti dampak penyelidikan tanah terbatas terhadap estimasi Bearing Stratum pada pondasi tiang pancang, merumuskan cara memetakan Bearing Stratum dengan
Dana Alokasi Khusus Non Fisik Bantuan Operasional Penyelenggaraan Pendidikan Anak Usia Dini selanjutnya disebut DAK Non Fisik BOP PAUD adalah dana yang
2.1 Bahan dan alat yang digunakan Bahan-bahan yang digunakan pada penelitian ini adalah Hidroksipatit hasil sintesa kulit kerang menggunakan metode hidrotermal suhu
BAB III ANALISIS DAN PEMBAHASAN ... Sejarah Penyusunan Buku II Tentang Kewarisan Dalam Kompilasi Hukum Islam Dan Alasan Munculnya Bagian Sepertiga Bagi Ayah Dalam KHI Pasal 177
