unikernels Big Data Ebook free download pdf pdf
Teks penuh
Gambar

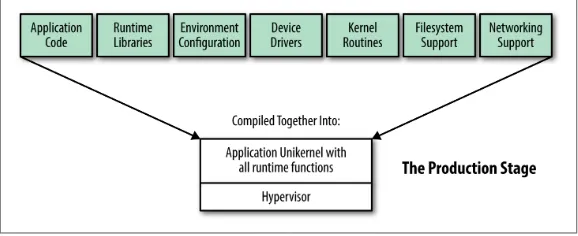
Garis besar
Dokumen terkait
Tujuan dari penelitian ini adalah (i) untuk mencari tahu kemampuan menulis teks deskriptive siswa kelas sepuluh SMA N 2 Kudus pada tahun ajaran 2013/2014 dengan
Bobot set el ah pemot ongan yang mencakup bobot bagi an- bagi an kar kas ( hasi l penyembel i han unggas yang di ber si hkan bul u dan kot or annya, t anpa kepal a, l eher , cakar ,
Hasil terbaik yang di peroleh dari pengambilan lignin pada batang rumput gajah ini di hasilkan oleh pelarut dengan konsentrasi 6% pada waktu 6 jam yang menghasilkan randemen sebanyak
Setelah diberi layanan orientasi pada sikus I, aktivitas belajar terhadap penggunaan internet peserta didik meningkat tetapi belum maksimal dengan rata-rata
Hasil penelitian yang dapat di simpulkan adalah pembagian waris menurut hukum Islam dan Kitab Undang-Undang Hukum Perdata sangat berbeda baik itu secara prinsip maupun
mempertimbangkan lingkungan dimana lokasi itu berada. Dekat dengan pusat kota atau perumahan, kondisi lahan parkir, lingkungan belajar yang kondusif dan transportasi.
Untuk meningkatkan populasi, produktivitas, dan reproduksi sapi pesisir perlu dilakukan perbaikan kualitas genetik ternak melalui seleksi, persilangan dengan bangsa
Prestasi belajar adalah hasil yang diperoleh dari suatu ativitas baik individu maupun kelompok yang mengakibatkan perubahan tingkah laku untuk kemajuan individu
