Computer Architecture and Security pdf pdf
Teks penuh
Gambar
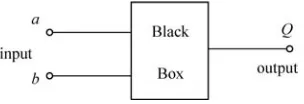
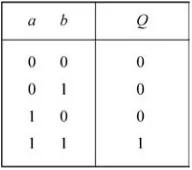
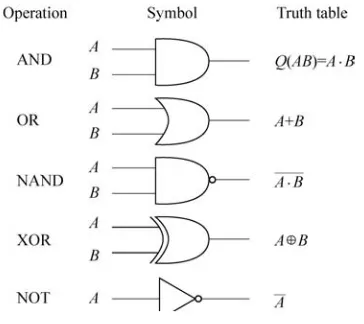

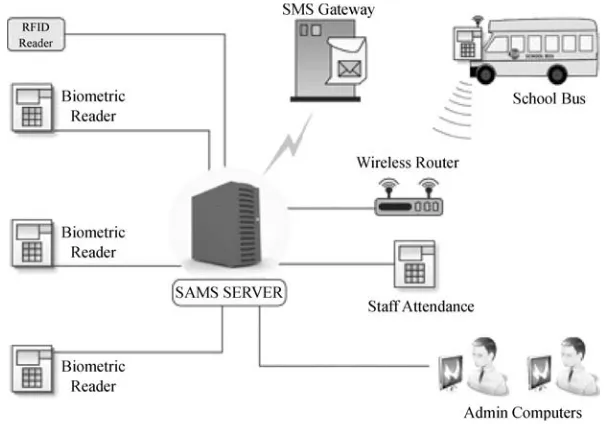


Garis besar
Dokumen terkait
Penerapan Model Pembelajaran Bebasis Portofolio untuk Meningkatkan Kreatiivitas Siswa Dalam Pembelajaran IPS.(Penelitian Tindakan Kelas di kelas 8-9 SMP Negeri 30
Dalam membangun kontribusi yang riil dari profesi arsitektur, Program Penghargaan IAI Jakarta 2018 ini memberikan apresiasi dan inspirasi untuk solusi dan pemikiran arsitektur
(B) Timbul arus induksi sesaat berlawanan arah dengan arus I dan kemudian menghilang (C) Timbul arus induksi yang makin besar (D) Timbul arus induksi yang makin kecil (E)
skripsi yang berjudul “ Tinjauan Yuridis Terhadap Penyitaan Aset Yang Tidak Terkait Tindak Pidana Pencucian Uang Oleh Komisi Pemberantasan Korupsi (Studi Kasus Perkara
Oleh karena itu, dibutuhkan suatu penelitian untuk mengetahui bagaimana perancangan front yard dari setiap Fakultas di Universitas Sumatera Utara dan bagaimana aktivitas
[r]
Yang menarik adalah dengan tingginya tekhnologi informasi sehingga sekarang ini untuk akses ilmu pengetahuan bisa melalui warung-warung internet yang menyediakan
Empat bola berjari-jari sama yaitu 10 cm terletak di atas meja sedemikian sehingga pusat dari keempat bola membentuk bujur sangkar bersisi 20 cm.. Bola kelima berjari-jari 10
