PENGELOMPOKAN CITRA KUPU-KUPU MENGGUNAKAN ALGORITMA AGGLOMERATIVE HIERARCHICAL CLUSTERING.
Teks penuh
Gambar
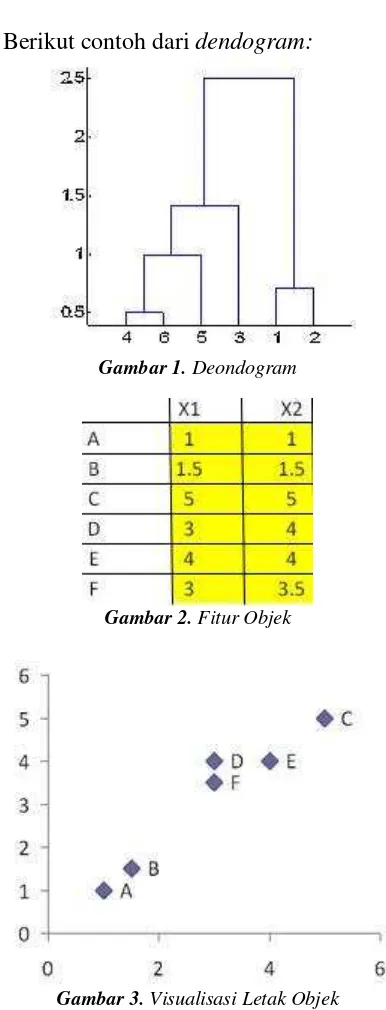
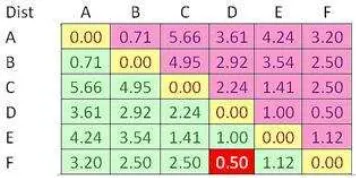
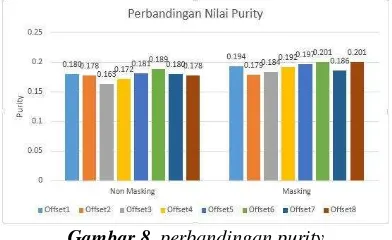
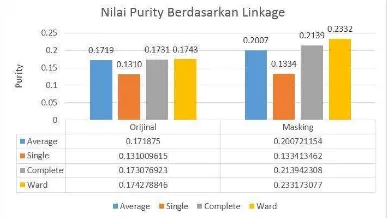
Dokumen terkait
Dengan MEC berbasis ekonomi kelautan yang memiliki 5 unit yaitu UPM (Unit Pemberdayaan Manusia), UPS (Unit Pengelolaan SDA), UPU (Unit Peningkatan Usaha), UPL (Unit
Tesis ini kami beri judul WANPRESTASI DAN PERBUATAN MELAWAN HUKUM; Studi Komparasi antara Hukum Islam dan Hukum Nasional dalam Penyelesaian Sengketa Ekonomi
Apakah data diperoleh dari sumber langsung (data primer) atau data diperoleh dari sumber tidak langsung (data sekunder). Pengumpulan data dapat dilakukan melalui beberapa
dilarang dalam Undang-Undang Nomor 5 Tahun 1999 tentang Larangan Praktek Monopoli dan Persaingan Usaha Tidak Sehat karena perjanjian ini dilakukan di antara
Aktivitas siswa dalam mengikuti plajaran setelah guru menggunakan model pembelajaran discovery leaning pada siklus 1 dapat dideskripsikan sebagai berikut: proses pembelajaran
Kegiatan Pendahuluan: Menjelaskan tujuan pembelajaran yang ingin dicapai, memberi pertanyaan untuk penjajagan, menjelaskan pentingnya materi ajar yang akan disampaikan.
(3) Untuk mengetahui hasil pengembangan pendidikan kedisiplinan di MTs Muhammadiyah Kemuning Tegalombo Pacitan. Untuk mengumpulkan data, penulis menggunakan beberapa
Visiting Scholar, Operations and Information Department, The Wharton School, University
