PENGELOMPOKAN CITRA RAMBU LALU LINTAS DENGAN HIERARCHICAL AGGLOMERATIVE CLUSTERING BERBASIS SCALE INVARIANT FEATURE TRANSFORM.
Teks penuh
Gambar
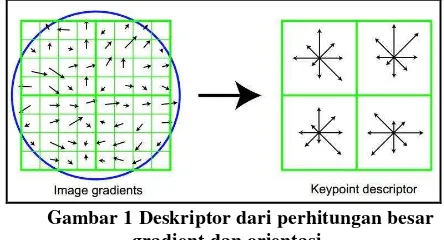

Dokumen terkait
Glukosa merupakan zat yang sangat dibutuhkan oleh tubuh. Hal ini dikarenakan gula memiliki begitu banyak fungsi. Salah satunya yaitu sebagai sumber energi utama bagi
Pada bayi kurang bulan yang mendapat susu formula juga akan mengalami peningkatan dengan puncak lebih tinggi dan lebih lama, demikian juga penurunannya jika tidak
Contoh penerapan teori sistem sebagai hal yang mempertegas dan memperjelas antara deskriptif dan preskriptif pada suatu permasalahan yang sedang dikemukakan
Semua teman penulis termasuk Oka Mahendra, Olin, Evy dan Charaka yang sudah terlebih dahulu mendapatkan gelar sarjana yang telah banyak membantu dalam menyelesaikan
Setelah ditemukan bahwa ada kata umpatan dalam Pilkada Sumut 2018 yang didominai oleh pengguna Twitter berjenis kelamin laki-laki, maka langkah analisis yang dilakukan lebih
Data yang digunakan dalam penelitian ini adalah data dari 143 perusahaan yang terdaftar di BEI (Bursa Efek Indonesia), maka dapat ditarik kesimpulan bahwa dalam
This study aims to analyze the influence of liquidity, free cash flow, firm size, and life cycle toward the dividend policy of consumer goods industry at Indonesia Stock
Menjalani bisnis ebay sebagai reseller, yaitu kita menjual kembali produk yang telah dijual oleh perusahaan lain (dropshipper), sehingga kita tidak perlu memiliki
