Analisis performasi algoritma winnowing dan algoritma manber untuk deteksi kesamaan dokumen teks berbahasa Indonesia
Teks penuh
Gambar
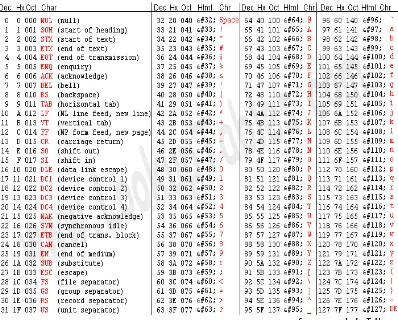
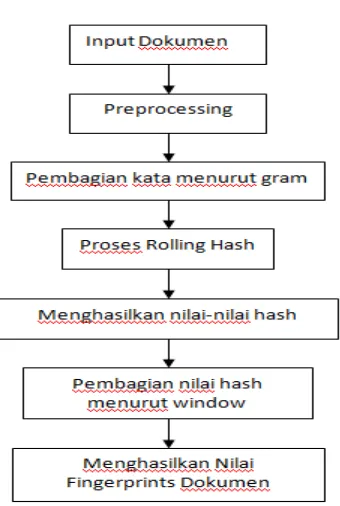
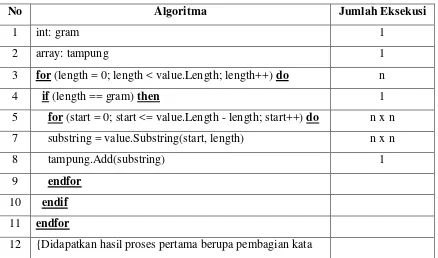
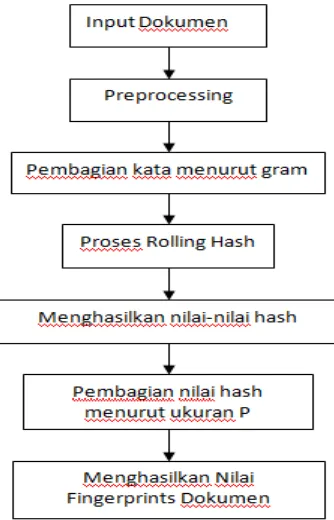

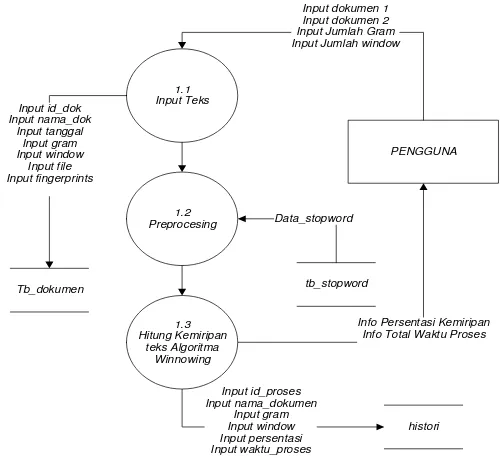
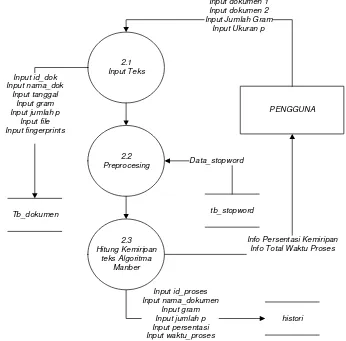



Dokumen terkait
Keadaan lingkungan yang buruk, pemukiman penduduk yang kotor, serta minimnya pengetahuan masyarakat tentang cara hidup sehat menyebabkan penyakit pes dapat menjalar
b) Mengingat keseluruhan bagian berada dalam pengendalian dari panitia teknis yang sama, maka pemakaian acuan yang tidak mencantumkan tahun (lihat 6.6.7.5.3) diperbolehkan,
Dalam kehidupan politik, musik dapat berfungsi sebagai kontrol sosial dengan cara melakukan kritik sosial dalam mengungkapkan beragam persoalan yang terjadi di masyarakat..
Pola ini adalah pola terakhir yang di gunakan dalam mendidik anak, sesuai yang terdapat dalam Hadits nabi bahwa pola ini adalah langkah terakhir yang di gunakan
Penelitian ini dilakukan dengan mesin pengering menggunakan rak yang berputar (rotari), dimana rak yang berputar ini akan memutar lada yang ada didalamnya selama
Ini merupakan satu persoalan utama bagi mereka yang tidak memahami bagaimana model 4MAT dapat membantu dalam menghasilkan pengajaran mata pelajaran Sejarah yang lebih efektif
Processor Intel® Pentium® M Processor yang ditujukan untuk notebook ini dikenal dengan Pentium M tahun 2003. Merupakan processor yang dirampingkan hingga 77 juta transistor. Pentium
Saya telah diminta untuk berpartisipasi dalam penelitian ini sesuai dengan.. judul
